100% Security Verified | No Subscription Required | No Malware
100% Security Verified | No Subscription Required | No Malware


Have you ever wondered how you can voice-search an item on Google? The ease of controlling your phone with your voice, even when your hands are full, is possible through Automatic Speech Recognition(ASR) technology.
ASR may seem like just a regular speech-to-text tool, but it's more than that. Basic speech-to-text simply converts spoken words into text. It often requires clear pronunciation and limited background noise for accurate results.
However, ASR, on the other hand, uses artificial intelligence (AI) and machine learning to increase accuracy, recognize different accents, filter out background noise, and even understand context. As a result, it can be integrated into virtual assistant tools, customer service bots, voice search, etc.
This article will show you how ASR works and how to use Automatic Speech Recognition systems for your different needs.
In this article
Part 1: What is an Automatic Speech Recognition System and How Do They Work?

Automatic Speech Recognition converts spoken words into text using AI, machine learning, and linguistic models to process and interpret speech. They're the foundation of voice assistants like Siri and Alexa, a key part of transcription services, call center analysis, and even real-time language translation tools.
ASR systems analyze audio input, identify speech patterns, and translate them into text. However, the process isn't as simple as just listening and typing the speaker's words.
How do ASR Systems Work?
- First, an ASR system records your speech using a microphone. In some cases, you're allowed to upload an audio file.
- Next, the audio is cleaned up to reduce noise and improve clarity.
- Then, the system analyzes the audio into framesand extracts key features such as the pitch, tone, and rhythm.
- The ASR system matches the extracted features with its acoustic model. Acoustic models are trained to recognize speech patterns and phonemes.
- Language models are used to predict the most likely word combinations based on grammar, common phrases, and syntax rules. For example, if someone says, “recognize speech,” an ASR system ensures it doesn’t confuse it with “wreck a nice beach”.
- Finally, the system uses a decoding algorithm to match the processed audio with the most likely output based on the audio and linguistic data. All these happen within nanoseconds.
The best ASR systems use deep learning to refine their predictions over time, learning from user corrections and increasing their accuracy with each use.
Part 2: Common Myths About ASR Systems vs Facts
Automatic Speech Recognition has advanced and become integrated into different industries over the years. But there are still several misconceptions about how it works and how it should be used.

Now, let's separate fact from fiction!
| Myths | Facts |
| ASR Systems are 100% accurate | Even the most advanced ASR systems, like those used by Google or OpenAI, can make mistakes. Background noise and overwhelming accents can all cause errors. So, while most AI-driven models have improved in accuracy, they still require supervision, review, and post editing tools—although not often |
| ASR systems understand languages just like humans | ASR systems DON'T understand language like humans do. They analyze patterns and probabilities derived from large datasets. They operate through statistical models—Hidden Markov Models (HMM) or the advanced deep neural networks used today—that map sounds to words. Hence, while they mimic humans, they lack a genuine understanding of the meaning behind the transcribed words |
Part 3: How to Use Automatic Speech Recognition Technology
As mentioned, Automatic Speech Recognition technology goes beyond voice commands and basic voice-to-text. It is integrated into different tools to ease processes in various industries. Below is the detailed process on how ASR technology is applied in video editing.
Video editing software with ASR - Filmora
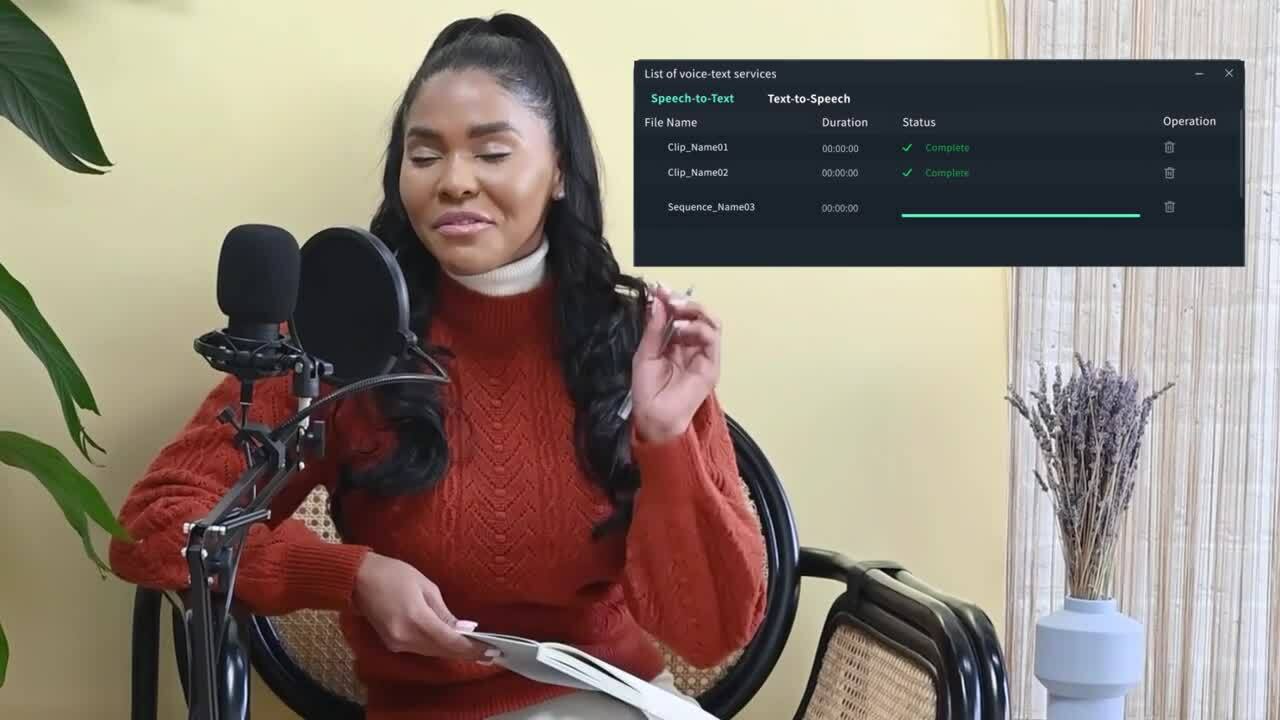
ASR technology has made it easier for video editors and creators to add subtitles, transcriptions, and voice-overs to videos. Video Editing tools like Filmora by Wondershare have in-built ASR systems that make this easy while offering other editing options.

Filmora is a video editing tool that offers professional-level editing with intuitive features that streamline your editing process. Its AI-powered speaker detection feature uses ASR to identify different speakers in a video and automatically transcribe them to create text captions/subtitles. This way, video editors can edit dialogues faster, saving them time.
Filmora for Mobile Filmora for Mobile Filmora for Mobile Filmora for Mobile Filmora for Mobile
Edit Videos on Your Mobile Phone with 1-Click!
- • Powerful Brand New AI Features.
- • User-friendly video editing for beginners.
- • Full-featured video editing for professional.


Here's how to use Filmora's mobile ASR technology to streamline your video editing process.
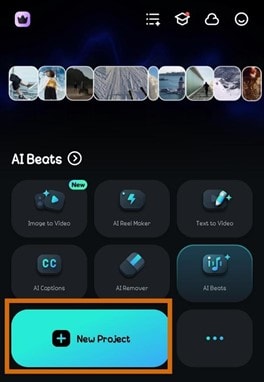
- Step 1: Open Filmora on your phone and select New Project. Import the video you want to edit to Filmora.
 secure download
secure download

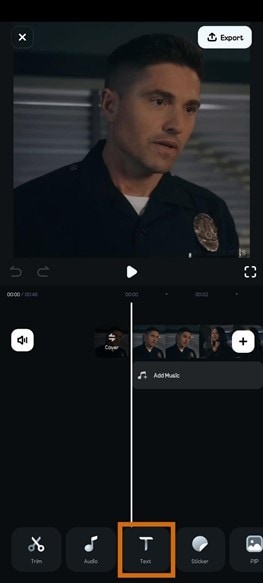
- Step 2: Click on Text and select AI Captions.
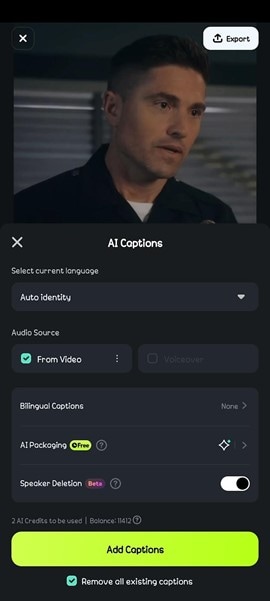
- Step 3: You can choose to indicate the language spoken in your video or let Filmora auto-identify it. Click on Add Captions. It may take a few seconds for Filmora to detect the speakers in your video and generate captions.
- Step 4: Click on Template to select a template for your text captions.
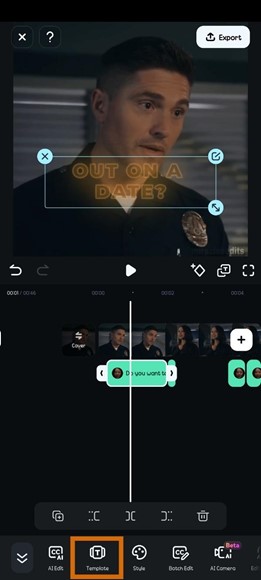
- Step 5: You can select which captions to apply the template to. You can also apply different templates to different captions. Click Apply.
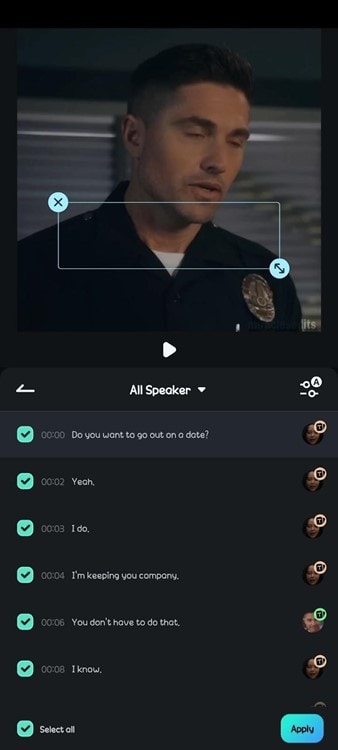
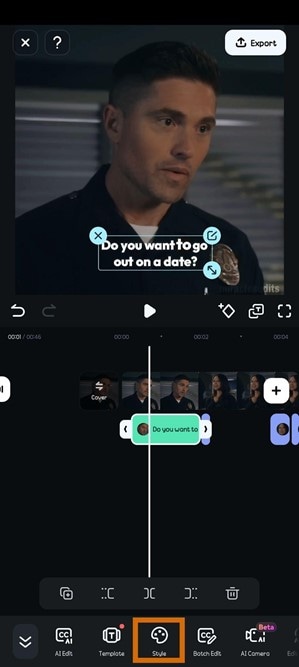
- Step 6: Move the captions on the video to adjust their placement. You can edit caption text by selecting Style on the toolbar.
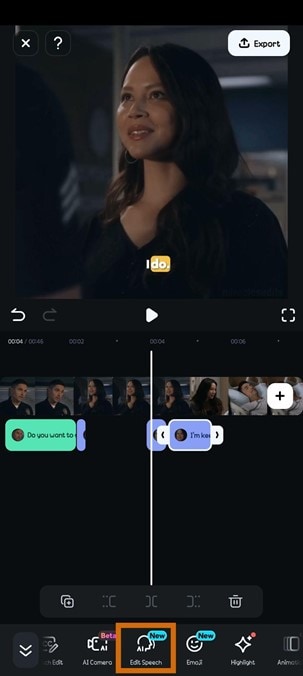
- Step 7: Click on Edit Speech to make any corrections and improve speech accuracy. Match the edited speech to the speaker in the video or clone a voice. Once done, click on Update Speech. This should take a few minutes.
An equivalent to this feature on desktop Filmora is the Speech-to-Text feature. Here’s how to use Filmora’s ASR integration on its desktop version.
- Step 1: Launch Filmora on your computer. Click on New Project on the home screen. Import your video to Filmora and upload it on the timeline.
 secure download
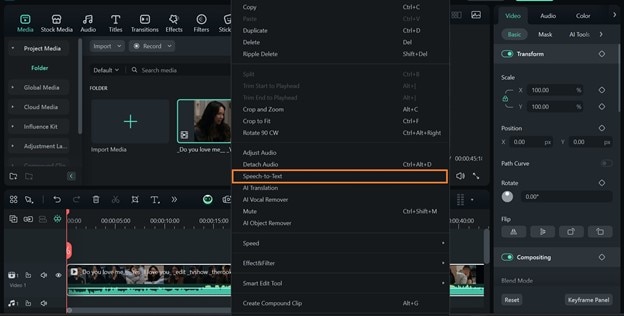
secure download - Step 2: Right-click the video on the timeline and select Speech-to-Text.
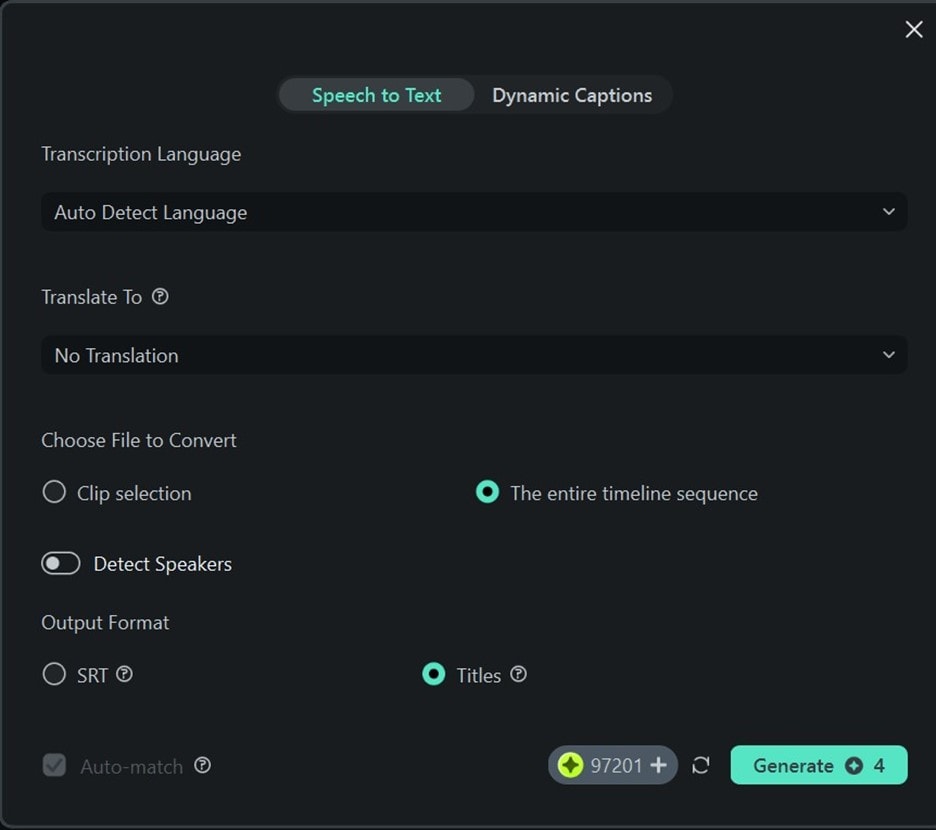
- Step 3: Ensure you set the output format to Titles and hit Generate.
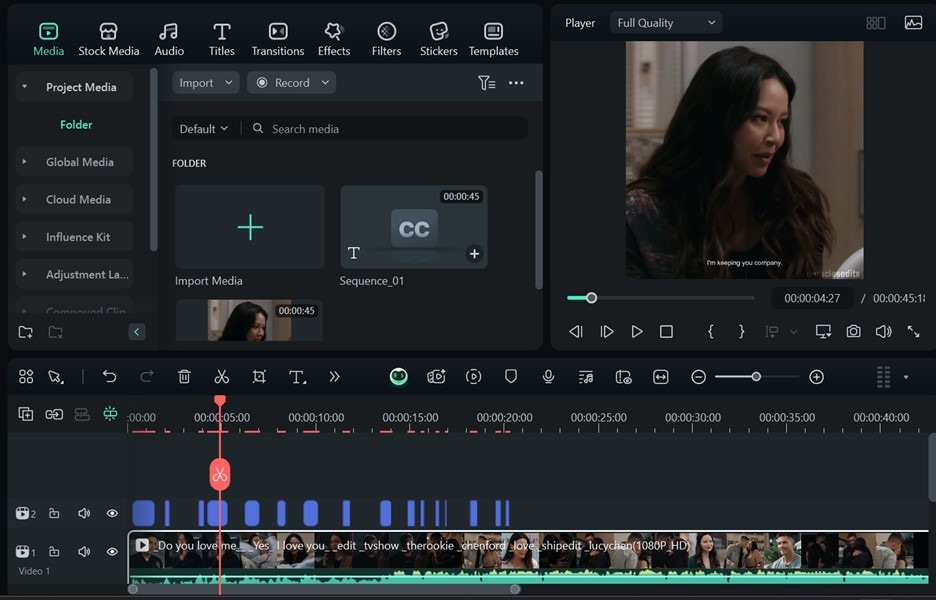
- Step 4: The transcribed text will be added to your video.
Part 4: Challenges with ASR Applications & Future Progressions

Automatic Speech Recognition technology has made life and work easier and more convenient. However, it still faces several challenges that affect its use and accuracy.
- Different accents and dialects:Variations in pronunciation, intonation, and slang can lead to misinterpretations.
- Poor audio quality and background noise: Overlapping sounds, background noise, and echoes can cause errors in transcription, reducing ASR performance.
- Homophones:Words that sound alike but have different meanings can be a problem for some ASR systems. For example, words like “there" “their", “two" and “too" can be easily confused, especially without contextual cues. This can lead to inaccurate transcriptions.
A potential solution to this is developing enhanced or more advanced acoustic models that account for a wider range of accents and dialects. In addition, developers could integrate natural language processing (NLP) in less advanced ASR systems. This would enable them to consider contexts and differentiate between homophones more accurately.
Enhancing Audio Quality with Filmora
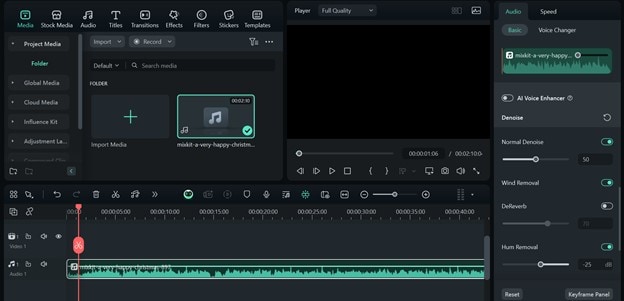
For ASR tools that allow audio clip uploads, you can solve the problem of background noise and low-quality audio using third-party tools like Filmora. Here’s how;
Open Filmora and upload the recorded audio. Drag and drop the audio on the timeline. Click on the audio clip on the timeline and go to the editor panel to your right. Turn on Auto Normalization. Enable Denoise, Wind Removal, and Hum Removal to get clear audio. Then, Export the audio clip. Make sure to set the export format to mp3.
Conclusion
Automatic Speech Recognition technology has changed the way we interact with technology. From basic transcriptions to advanced specialization in various industries, ASR has increased our productivity and efficiency.
Filmora, for example, has made video captioning easy and more reliable with its speaker detection feature. Combine this with its audio enhancement feature, and you have a power tool that transforms your videos and audio. Despite the challenges these ARS systems face, future advancements promise improved and enhanced speech recognition.
secure download