


 100% Security Verified | No Subscription Required | No Malware
100% Security Verified | No Subscription Required | No Malware

If you are someone working in fields that require fast and accurate transcriptions, integrating speech-to-text APIs into your workflow must be what you need. Thankfully, many of these APIs provide a free option, so you can use them to streamline your transcription process without straining your budget.
To sort them out, we have compiled a list of the best free speech-to-text APIs available, along with their key features, limitations, and how to integrate them into your projects. Even if you find that these options don’t meet your needs, we also provide alternative recommendations that may be better suited to your requirements.

In this article
Part 1. Best Free Speech-to-Text API for Audio Transcription
With the growing demand for audio transcription in various fields such as content creation, education, and business, one common question many users ask is, "What are some free APIs or online services for speech-to-text conversion?"
Speech-to-text APIs are essential for developers to integrate speech-to-text functionality into their applications. In response to this need, we look into an in-depth overview of the top free speech-to-text APIs available today. These include Google Cloud Speech-to-Text, Microsoft Azure Speech Service, Speechmatics, AssemblyAI, and AWS Transcribe.
1. Google Cloud Speech-to-Text API
The Google Cloud Speech-to-Text API is part of the Google Cloud suite, designed to convert audio into accurate text transcriptions. With user-friendly APIs, developers can integrate speech recognition capabilities into their applications. To use this speech-to-text API for free, Google gives users 60 minutes of free transcription. New users can also explore Speech-to-Text and other Google Cloud products with up to $300 in free credits.
Key Features:
- Leverages Chirp, Google Cloud’s advanced speech model, trained on millions of hours of audio data and billions of text sentences
- Offers support for 125 languages and variants, making it suitable for a diverse user base
- Provides a selection of trained models tailored for specific use cases, including voice control, phone call transcription, and video transcription
- Utilizes model adaptation techniques to improve the accuracy of frequently used words, expand vocabulary for transcription, and enhance performance in noisy audio environments
Limitations:
- The free tier allows only 60 minutes of transcription per month. It may not be enough for larger projects or frequent transcription needs
- Less convenient for those unfamiliar with Google Cloud services. You need to upload audio files to a Google Cloud Storage Bucket before the transcription
- Advanced customization features may not be fully accessible in the free version
Ideal For: Low transcription needs, such as small businesses or freelancers transcribing short interviews, podcasts, or meetings.
2. Microsoft Azure Speech API
The Microsoft Azure Speech API is part of Azure's suite of cognitive services. For using it for free, Microsoft Azure Speech API offers a free tier with limited usage. The tier is ideal for small projects, testing, and learning purposes. It includes features like real-time transcription and customizable voice models. You can visit Microsoft Azure's pricing page for more details.
Key Features
- Retrieve logs for each endpoint upon request for that specific endpoint
- Access the manifest of the models you create to set up on-premises containers
- Upload data from Azure storage accounts using a shared access signature (SAS) URI
- Use your own storage accounts to manage logs, transcription files, and other data
- Batch transcribe audio files from multiple URLs or an Azure container
Limitations
- The free tier allows hosting only one custom voice model per month and only 5 audio hours for free per month
- While Azure's transcription is generally accurate, it occasionally struggles with spelling out words correctly
- The initial setup of the Azure Speech API can be complex
Ideal For: Industries like healthcare, finance, or legal services where specialized terminology is frequently used.
3. Speechmatics
Speechmatics offers a speech-to-text API with a generous free plan, providing users with 8 hours of transcription per month. This plan includes 4 hours for batch processing and an additional 4 hours for real-time transcription. Designed for flexibility, Speechmatics caters to various applications, from media production to customer service. You can leverage its advanced machine-learning algorithms to achieve high accuracy and reliable results, even in challenging audio environments.
Key Features
- Supports around 50 languages, offering extensive coverage for various accents and dialects.
- The API delivers real-time transcription with a latency of less than one second
- Automatically identify the language being spoken
- Each word in the transcription is accompanied by a precise timestamp
- Export transcripts as SRT captions
Limitations
- Setting it up involves configuring custom interfaces, making it more suitable for enterprises with technical resources.
- Not suitable for smaller businesses or projects due to technical requirements
Ideal For: Large-scale enterprise transcription needs.
4. AssemblyAI
AssemblyAI provides AI-driven speech models through an API. If you are a new user, you’ll receive a $50 free credit to start. This API supports various voice data tasks. They include Speaker Diarization, Topic Detection, Sentiment Analysis, and Text Summarization. There are two Speech-to-Text options available: "Best" for high accuracy and "Nano" for cost-efficient transcription.
Key Features
- Speaker Diarization to help identify and separate different speakers in an audio recording
- Custom spelling and vocabulary where you can input custom words or specialized terminology for accurate transcription
- Automatically censors inappropriate language and applies correct punctuation and casing for easier readability
Limitations
- The platform offers fewer languages compared to some competitors
- Occasional bugs and issues can take time to be addressed or resolved
- The tool often struggles with transcription accuracy when audio has significant background noise or disturbances
Ideal For: Transcribing meetings, interviews, or podcasts involving multiple speakers.
5. AWS Transcribe
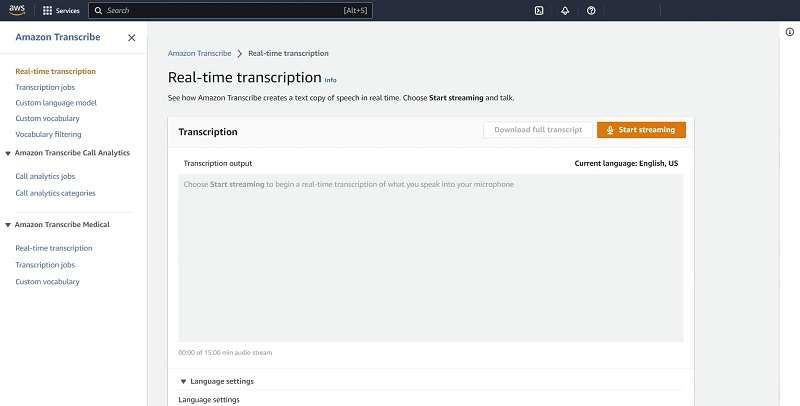
Amazon Transcribe, part of AWS, allows new users one hour of free transcription each month during their first year. This service lets users convert audio to text for various needs, though it does require audio files to be stored in Amazon S3.
Key Features
- Punctuation and formatting options
- Custom vocabulary for industry-specific terms
- Multi-speaker identification
- Transcribes live audio streams or pre-recorded speech into text
Limitations
- Requires audio storage in Amazon S3
- May miss specific words, especially proper nouns or named entities (NER)
Ideal For: Businesses needing automated transcription for meetings, media, or customer support
Part 2. How to Get Started with Speech-to-Text API Integration
To get started with integrating Speech-to-Text API, each service usually provides detailed documentation and resources to guide developers through the setup process. You’ll usually begin by creating an account with the provider. Then, generate an API key that grants access to the service.
As a demonstration, one of the most popular speech recognition APIs, Google Cloud Speech-to-Text, provides Google Cloud Speech-to-Text API documentation here. The process involves several key steps:
- Create a Google Cloud Project: Sign up for a Google Cloud account and create a new project in the Google Cloud Console. This project will manage your API-related resources.
- Enable the Speech-to-Text API: Navigate to the API & Services section, search for the Speech-to-Text API, and enable it for your project.
- Generate API Credentials: Create a service account and generate an API key, which you will use to authenticate your requests. Download the key file (usually in JSON format) to store your credentials.
- Set Up the Client Library: Install the necessary client libraries (such as Python, Java, or Node.js) to interact with the API programmatically. The client libraries simplify making API requests and handling responses.
- Write Code to Transcribe Audio: Use the API key and client library to write code that converts audio into text by sending audio data to Google Cloud’s servers for processing.
Watch the full tutorial here on how to integrate Google Cloud free speech-to-text API into your app.
Part 3. Best Solution to Use Speech-to-Text Without API Integration
Not every user or business needs to integrate APIs, as the setup can be complex, time-consuming, and sometimes unnecessary for smaller projects or individual users. Instead, there is another way of converting speech to text without API integration. One such option is Wondershare Filmora's Speech-to-Text feature.
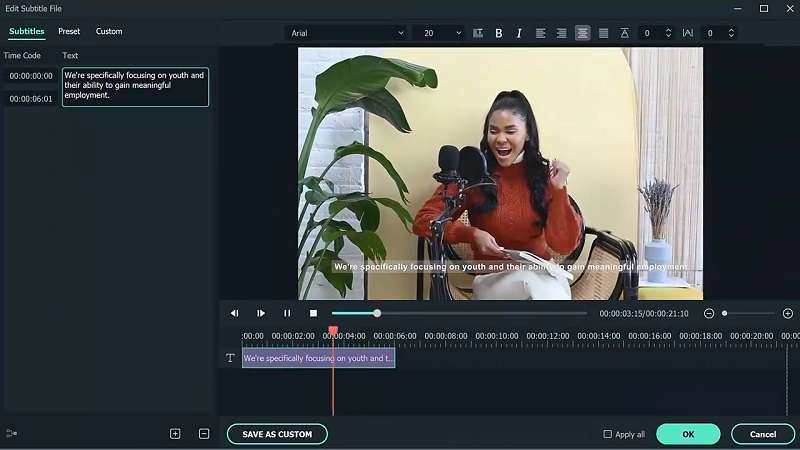
Filmora's Speech-to-Text Feature
Filmora is a popular video editing tool that comes with a built-in speech-to-text feature. You can use it to convert spoken words in audio or video files directly into text. This feature is a hassle-free solution to quickly generate subtitles, captions, or transcripts. You don’t have to worry about manual transcription or complex setups — the process is fully automated.
Additionally, if you’re working on multilingual projects or need to transcribe content in different languages, Filmora's speech-to-text also supports multiple languages. They include English, French, Spanish, Indonesian, Hindi, Japanese, and more.
When to choose Filmora speech-to-text feature over API integration?
- Non-technical Users: If you don’t have a technical background or a development team, Filmora’s easy-to-use interface eliminates the need for API integration.
- Quick Turnaround Projects: When you need to transcribe content quickly for subtitles, captions, or short video projects, Filmora’s fully automated process saves time compared to the manual setup of API services.
- Working with Video Content: Since Filmora combines video editing and speech-to-text capabilities in one platform, you can apply the transcribed text directly to your video projects for captions, subtitles, or transcripts without switching between tools.
Step by step using speech-to-text with Filmora
Step 1: Open Filmora and Import Your Audio File
Ensure you have the latest version of Filmora installed on your computer. Then, start by launching Filmora and selecting New Project to create a new project.
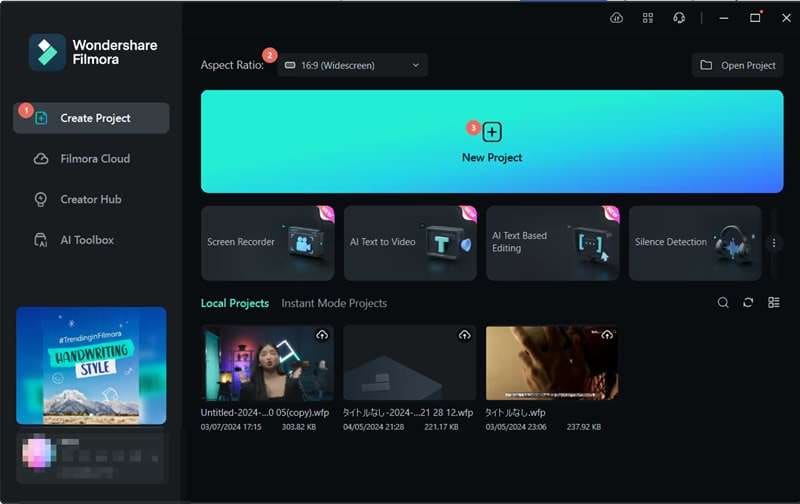
To upload your audio file, click Import and choose the file from your computer.
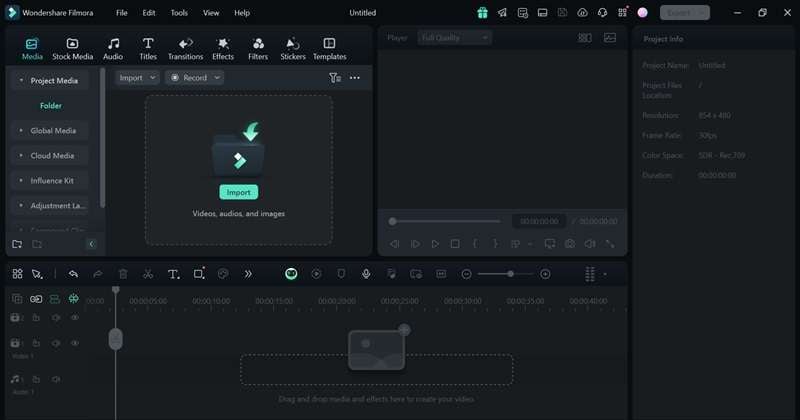
Step 2: Access the Speech-to-Text Tool
Once your audio file is imported, drag it into the timeline. To activate the speech-to-text tool, select the audio track on the timeline. Then, go to Tools > Audio > Speech to Text.
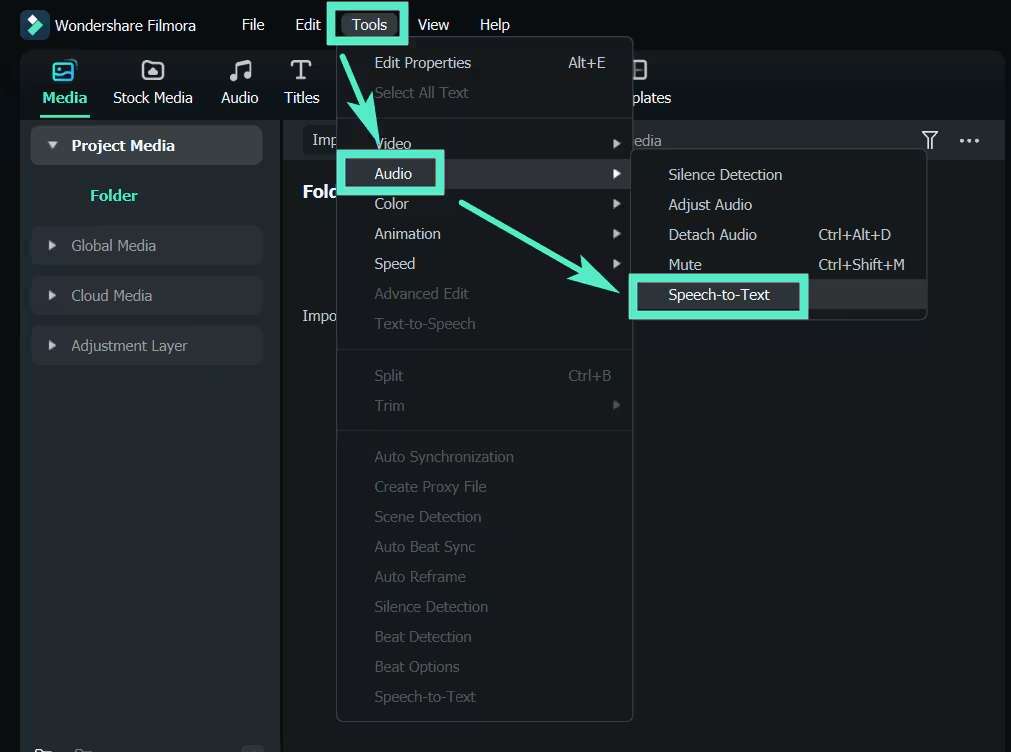
Step 3: Set Up the Transcription Preferences
A configuration window for the speech-to-text function will appear. Here, you can select the language of the audio file you are transcribing. If you do not need the speech to be translated, select the "No Translation" option under the “Language to be translated to” section.
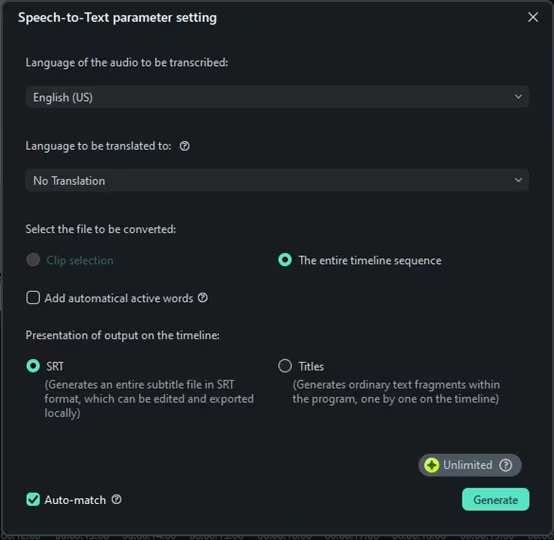
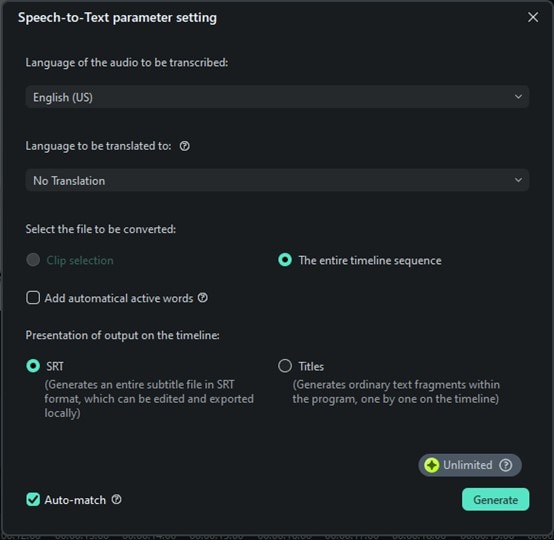
You can also decide whether to transcribe only the selected audio clip or the entire timeline. After that, choose your output format as an SRT file.
Step 4: Start Transcribing the Audio
Once all your settings are in place, click on the Generate button. Filmora will process the audio and create the transcription. When it is done, the transcription file will be available in the Media tab.
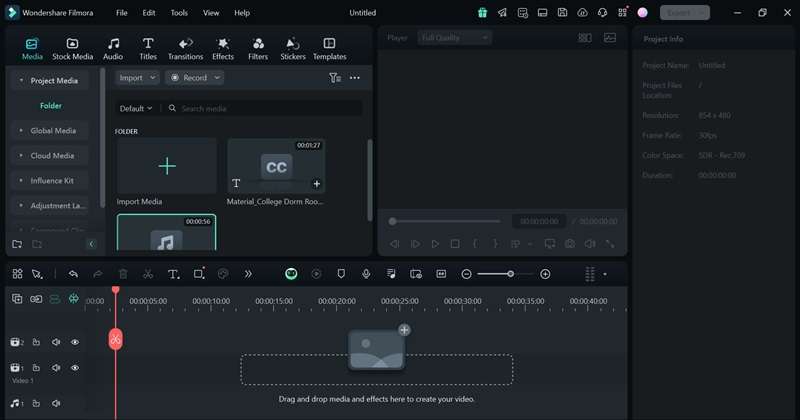
Step 5: Edit the Transcription
If you need to adjust the transcription, double-click on the generated transcription file to open the editing interface. Here, you can review the text and make necessary corrections.
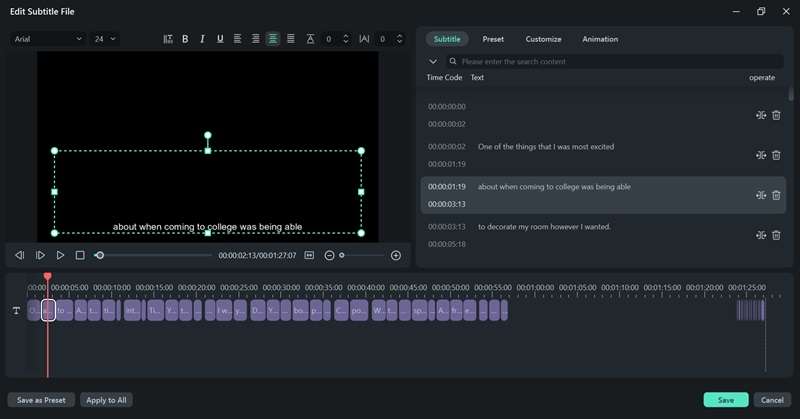
Step 6: Save or Add the Transcription to Your Project
After making all necessary edits, you can export the transcription as an SRT file. Right-click the text transcription track on the timeline and select “Export Subtitle File.”
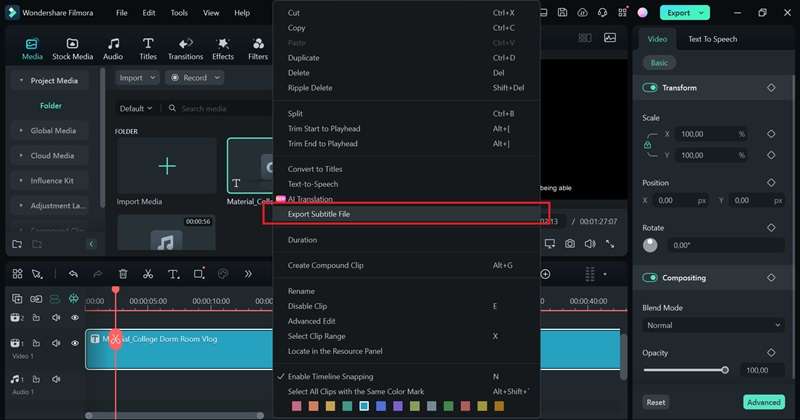
Conclusion
Free speech-to-text APIs help developers integrate transcription into their applications without incurring high costs. In today’s article, we’ve reviewed some of the best tools on the market, including Google Cloud Speech-to-Text, Microsoft Azure, Speechmatics, AssemblyAI, and AWS Transcribe. Whether you're working on small-scale projects or testing out speech recognition for your project, these free options are a solid starting point.
However, if you're looking for a more non-technical solution, Filmora’s built-in Speech-to-Text feature can be an excellent alternative. It simplifies the process, especially for video creators or businesses needing quick transcription without the complexity of API integrations.
