100% Security Verified | No Subscription Required | No Malware
100% Security Verified | No Subscription Required | No Malware

You’re editing a video with multiple speakers, maybe a podcast or an interview. Manually adding captions is tedious—you have to listen, type, and sync every spoken word. What if your video editor could automatically recognize different voices and generate captions for each speaker? That’s where speaker recognition in Python changes the game.
Python is the top choice programming language for developing voice-based applications due to its robust libraries. These libraries help you implement and deploy speaker recognition models for real-time speech processing, analysis, and speaker identification. For example, Pico Voice Eagle SDK delivers fast and precise speaker identification for AI-driven applications.
Alternatively, there are video editing platforms that integrate speech recognition artificial intelligence. They work by scanning the video’s audio, distinguishing speakers, and generating synchronized captions.
This guide will explore how to implement speaker identification in Python. We will also look at the best no-code alternatives for effortless video captioning.

In this article
Part 1: Fundamentals of Audio Processing

Every voice recognition system starts with audio processing. Sound travels as continuous analog signals, but computers require digital formats. To convert speech into data, we use sampling rates and audio encoding techniques.
A sampling rate defines how often sound is recorded per second. The standard for Python speaker recognition is 16 kHz, ensuring high accuracy. The format of the audio file also matters—WAV, MP3, and FLAC are common options, with WAV preferred for machine learning tasks.
Python simplifies real-time speaker identification with specialized libraries like PyAudio and Picovoice Eagle SDK. Using these tools, developers can capture, analyze, and train models for real-time speaker identification in Python.
Part 2: Real-Time Speaker Identification with Picovoice Eagle SDK
Picovoice Eagle SDK is a high-performance tool for speaker recognition in Python. Unlike traditional models, it processes audio locally. This SDK is crucial for real-time speaker identification in Python, especially in AI security systems and smart assistants.
Furthermore, it's lightweight and works seamlessly across multiple platforms, including Windows, macOS, Linux, Android, iOS, and even Raspberry Pi. You just need to sign up for the Pico Voice console and get your access key to authenticate your usage.
Installing and Setting Up Pico Voice Eagle SDK in Python
To integrate Picovoice Eagle SDK for speaker recognition in Python, install it first. Before you do this, ensure you have Python 3.6+ installed.
Open a terminal (Linux/macOS) or command prompt (Windows) and run:
| python --version |
or
| python3 --version |
If Python is installed, it will display something like:
| Python 3.8.10 |
If the version is 3.6 or higher, you're good to go.
To begin, install the necessary libraries. Run the following in your terminal:
| pip install SpeechRecognition pyaudio librosa pvrecorder |
For Picovoice Eagle SDK, download and install:
| pip install pvporcupine pveagle |
Step-by-Step Guide to Implementing Real-Time Speaker Identification Using Picovoice Eagle SDK in Python
- Step 1: Install Python. On the official Python website, select the option to download the most recent version, Python 3. x.x.
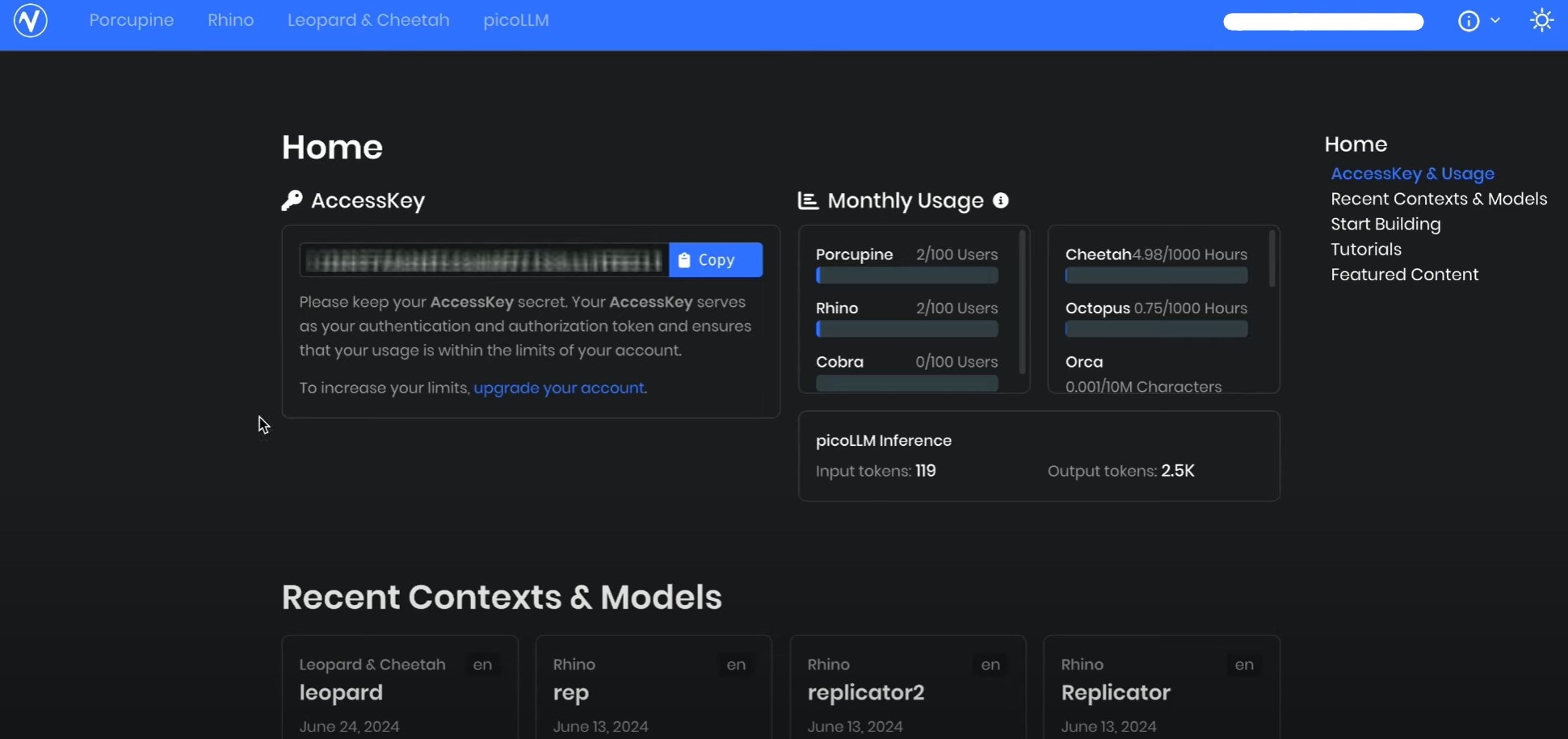
- Step 2: Next, sign up for a free Picovoice Console account and retrieve your Access Key. This key is required to authenticate your requests when using the Eagle Speaker Recognition SDK.
- Step 3: Install the necessary Python packages. Run the following command in your terminal:
| pip install pveagle pvrecorder |
This will install PV Eagle (for speaker recognition) and PV Recorder (for audio capture).
- Step 4: Create two files in your VsCode. The first file will be to enroll a speaker. Enrollment is the process of creating a speaker profile based on voice data. Follow these steps:
- Import the required libraries
- Initialize EagleProfile with your Access Key
- Use PV Recorder to capture voice samples
- Feed audio frames to EagleProfile until enrollment completes
- Export the speaker profile for future recognition
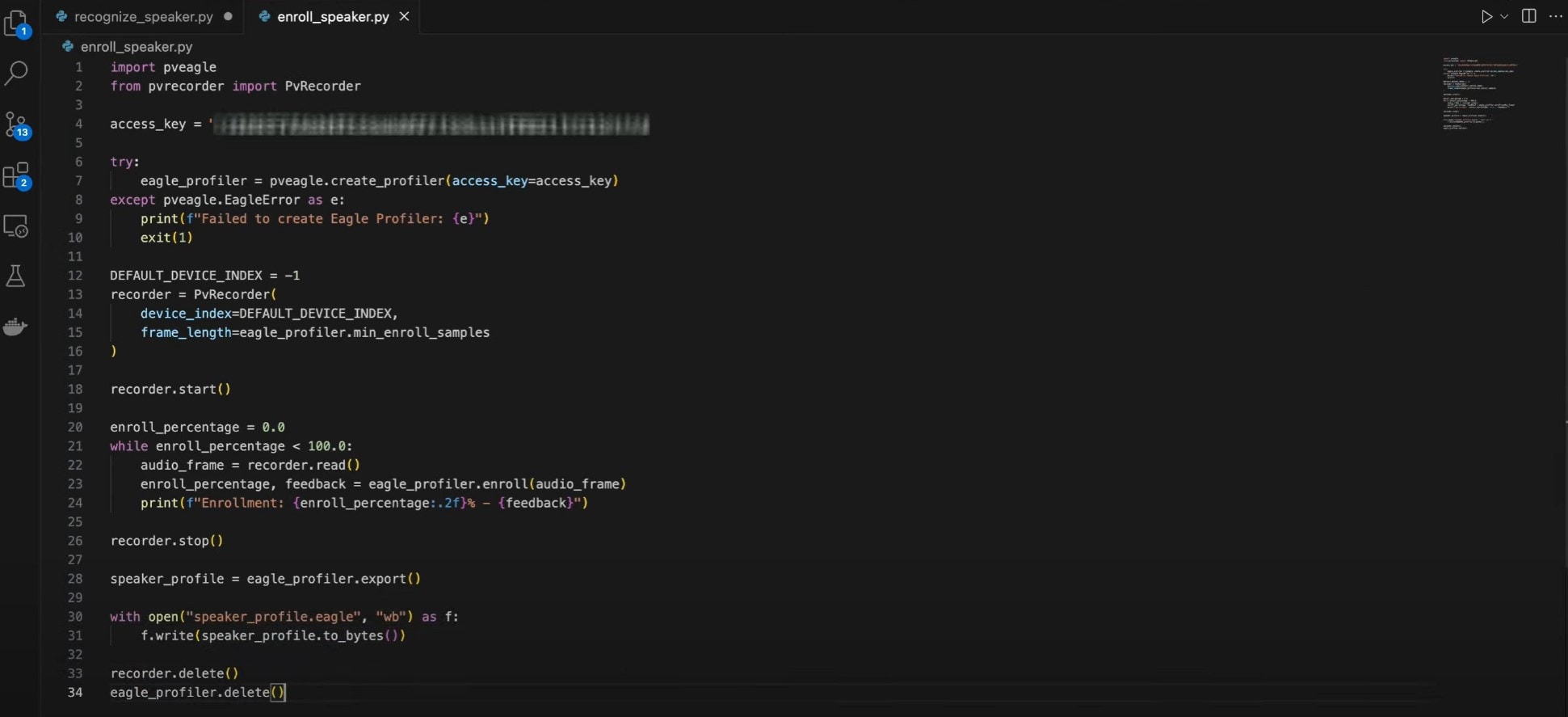
Here’s the code for speaker enrollment:
| import pveagle from pvrecorder import PvRecorder access_key = "YOUR_ACCESS_KEY" try: eagle_profiler = pveagle.create_profiler(access_key=access_key) except pveagle.EagleError as e: print(f"Failed to create Eagle Profiler: {e}") exit(1) DEFAULT_DEVICE_INDEX = -1 recorder = PvRecorder( device_index=DEFAULT_DEVICE_INDEX, frame_length=eagle_profiler.min_enroll_samples ) recorder.start() enroll_percentage = 0.0 while enroll_percentage < 100.0: audio_frame = recorder.read() enroll_percentage, feedback = eagle_profiler.enroll(audio_frame) print(f"Enrollment: {enroll_percentage:.2f}% - {feedback}") recorder.stop() speaker_profile = eagle_profiler.export() with open("speaker_profile.eagle", "wb") as f: f.write(speaker_profile.to_bytes()) recorder.delete() eagle_profiler.delete() |
- Step 5: Go to your terminal and record by entering the code below
| python3 enroll_speaker.py |
Once the script is running, try speaking into the microphone. If your voice matches the enrolled speaker profile, it will print "Speaker recognized!" Otherwise, it will indicate an unknown speaker.

- Step 6: Now that the speaker profile is ready, let’s create a code for real-time speaker recognition on the second file. This loads a speaker profile and recognizes a speaker in real time using the Pico Voice Eagle SDK.
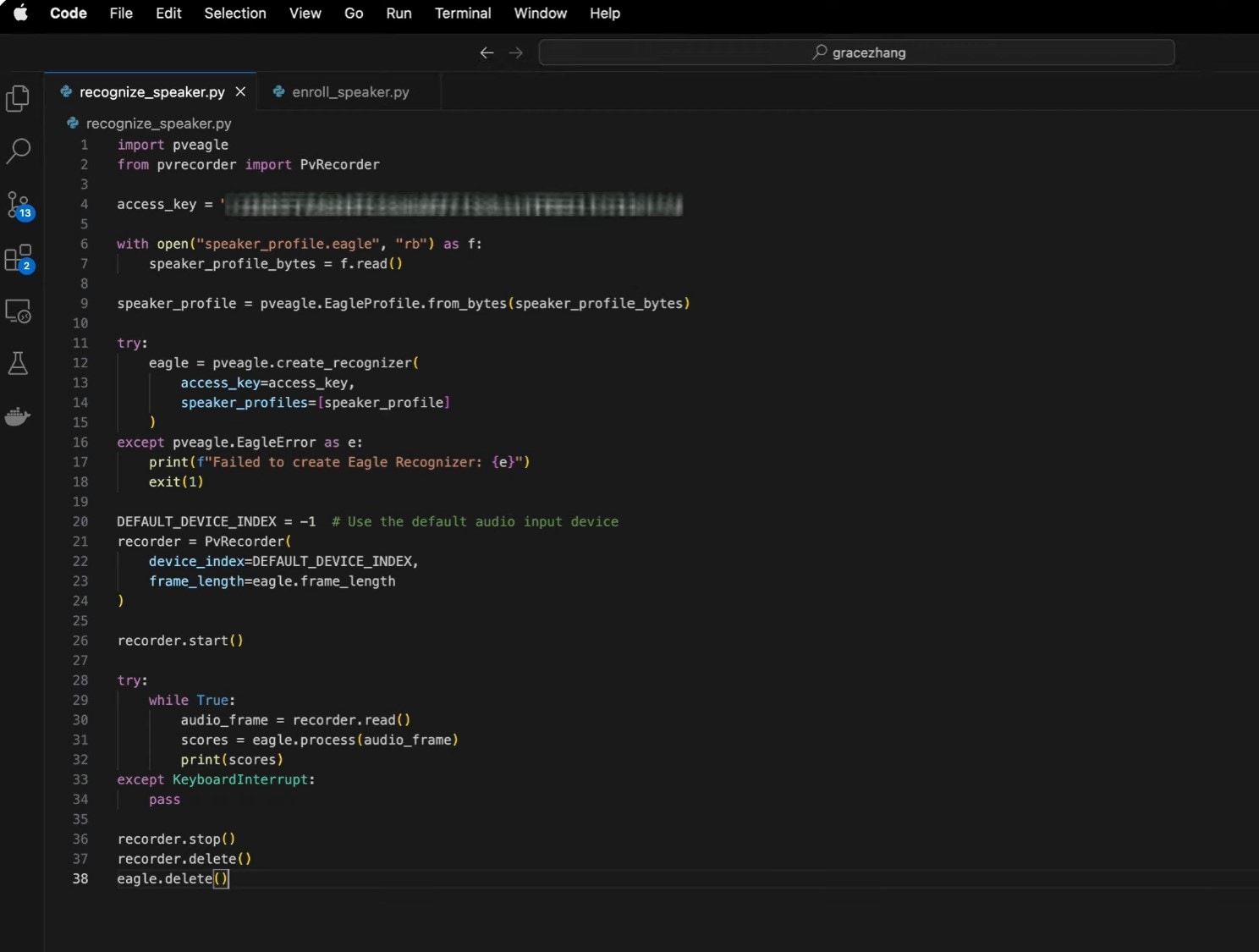
This involves:
- Creating an Eagle instance with your Access Key and Speaker Profile
- Using PV Recorder to capture live audio
- Passing the audio frames to Eagle for real-time recognition
Here is the code:
| import pveagle from pvrecorder import PvRecorder access_key = "YOUR_ACCESS_KEY" with open("speaker_profile.eagle", "rb") as f: speaker_profile_bytes = f.read() speaker_profile = pveagle.EagleProfile.from_bytes(speaker_profile_bytes) try: eagle = pveagle.create_recognizer( access_key=access_key, speaker_profiles=[speaker_profile] ) except pveagle.EagleError as e: print(f"Failed to create Eagle Recognizer: {e}") exit(1) DEFAULT_DEVICE_INDEX = -1 # Use the default audio input device recorder = PvRecorder( device_index=DEFAULT_DEVICE_INDEX, frame_length=eagle.frame_length ) recorder.start() try: while True: audio_frame = recorder.read() scores = eagle.process(audio_frame) print(scores) except KeyboardInterrupt: pass recorder.stop() recorder.delete() eagle.delete() |
- Step 7: Test and Run the Application.
| Python3 recognize_speaker.py |
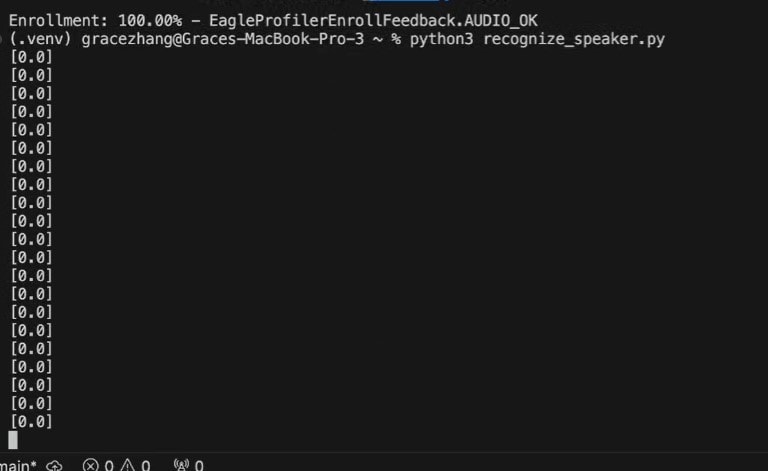
0 = Voice not recognized
1 = Voice recognized
Speaker identification in Python can only be understood and executed by professional programmers. You need to have a knowledge of programming to some extent to understand the process.
Part 3: Are There Easier Ways to Perform Speaker Recognition?
Building a Python speaker recognition system requires coding skills and technical knowledge. While identification in Python is powerful, it can be challenging for non-programmers. Many users prefer ready-made tools that offer similar speaker and speech recognition features. It is a better way of getting the task done without coding skills.
One such tool is WondershareFilmora, a video editor with built-in speaker recognition and speech editing. It allows users to detect, transcribe, and modify voice recordings without writing a single line of code.
Unlike Python speaker recognition, which requires manual model training, Filmora’s built-in tools automate the process. You can edit and enhance audio files without needing Python or machine learning knowledge. This makes speaker identification accessible to content creators, marketers, and business users.
Filmora’s Mobile Speaker Detection and Speech Edit Features
Filmora integrates an AI-powered tool that simplifies audio editing and speaker recognition. With its mobile version, users can access speaker detection and speech editing features.
- Speaker detection.Speaker Detection analyzes audio and distinguishes between different speakers. Instead of the manual way of listening and tagging voices, the AI identifies who is speaking and when.
- Speech edit. Editing speech can be tedious, but Filmora’s Speech Edit simplifies the process. It allows users to change voice recordings, adjust clarity, and remove background noise.
How to Recognize Voice, Convert to Text, and Edit Using Filmora on the Go
Filmora makes speaker recognition simple with a few clicks. Here’s a step-by-step guide:
- Step 1: Download Filmora, click on “new project, and import the video with voice.
 secure download
secure download

- Step 2: Select text to convert the spoken words into text.
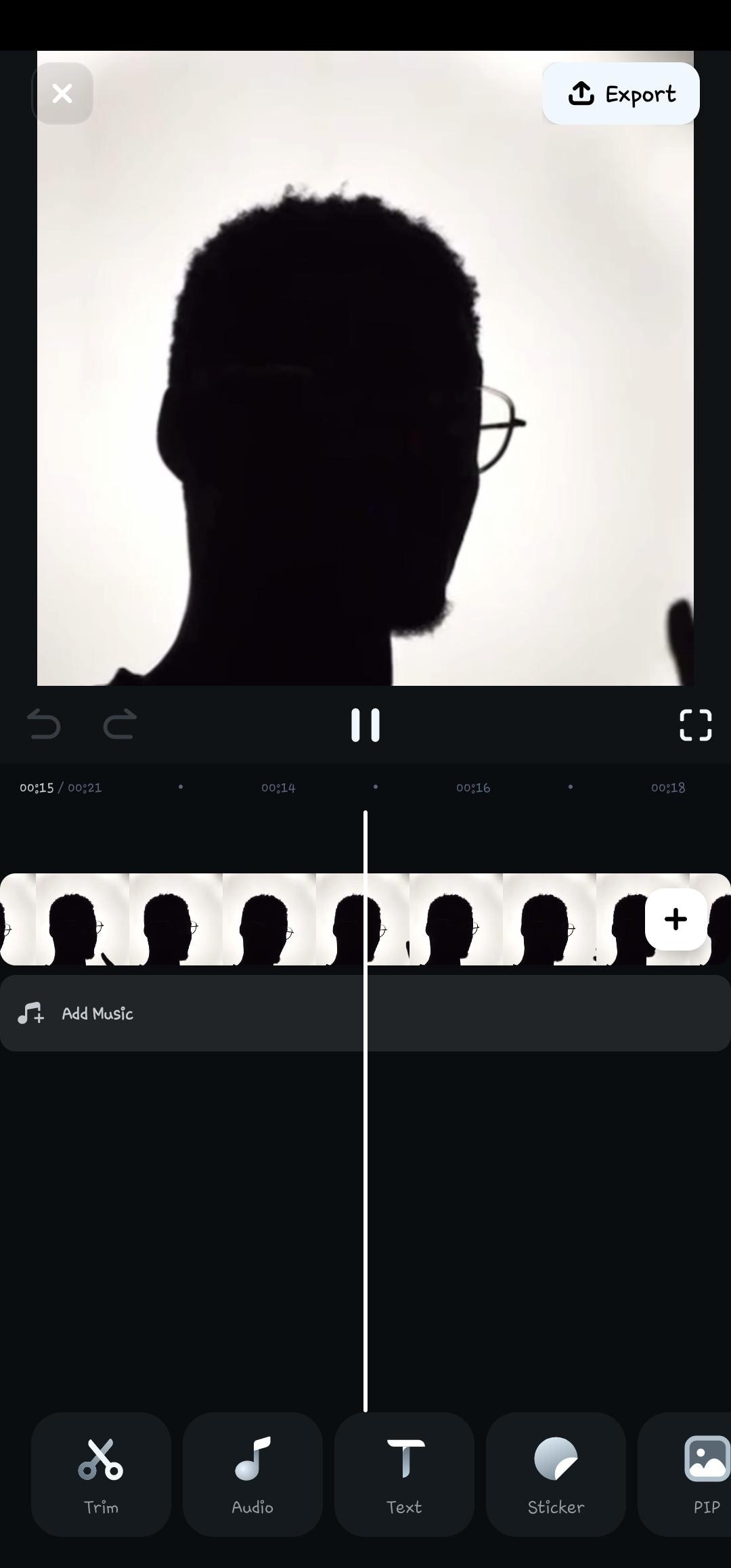
- Step 3: Click on AI captions to start the voice recognition process
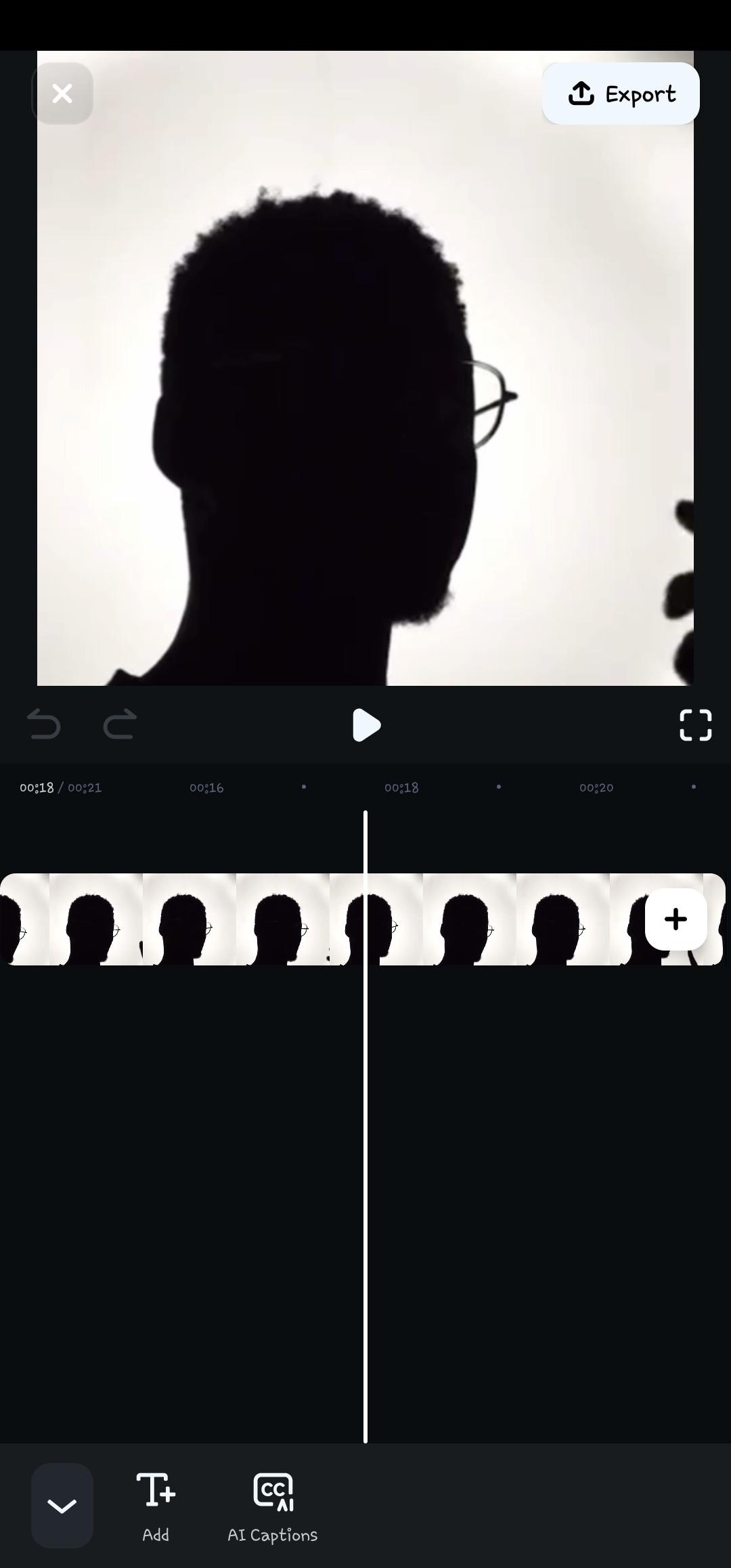
- Step 4: Click on the Speaker Detection option before selecting Add Captions
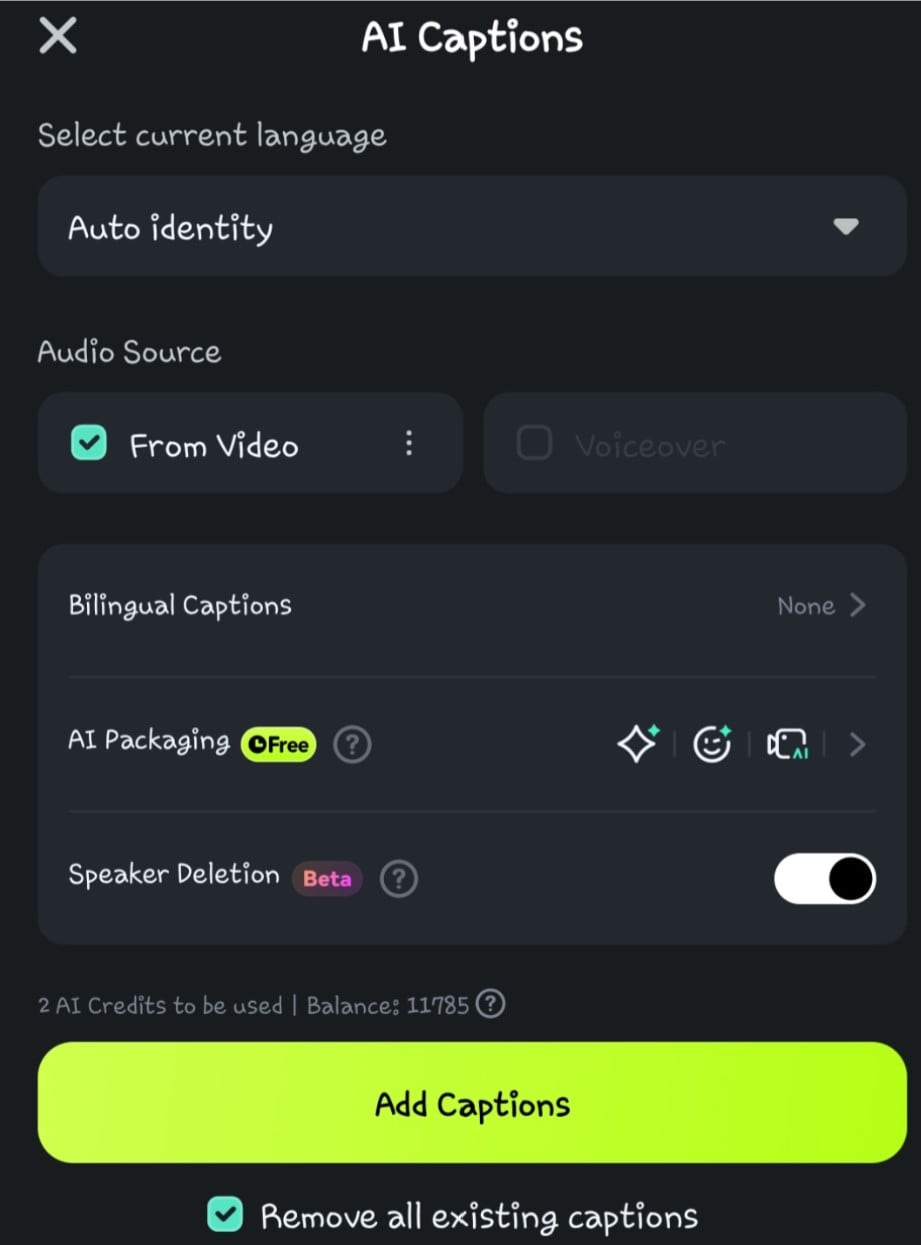
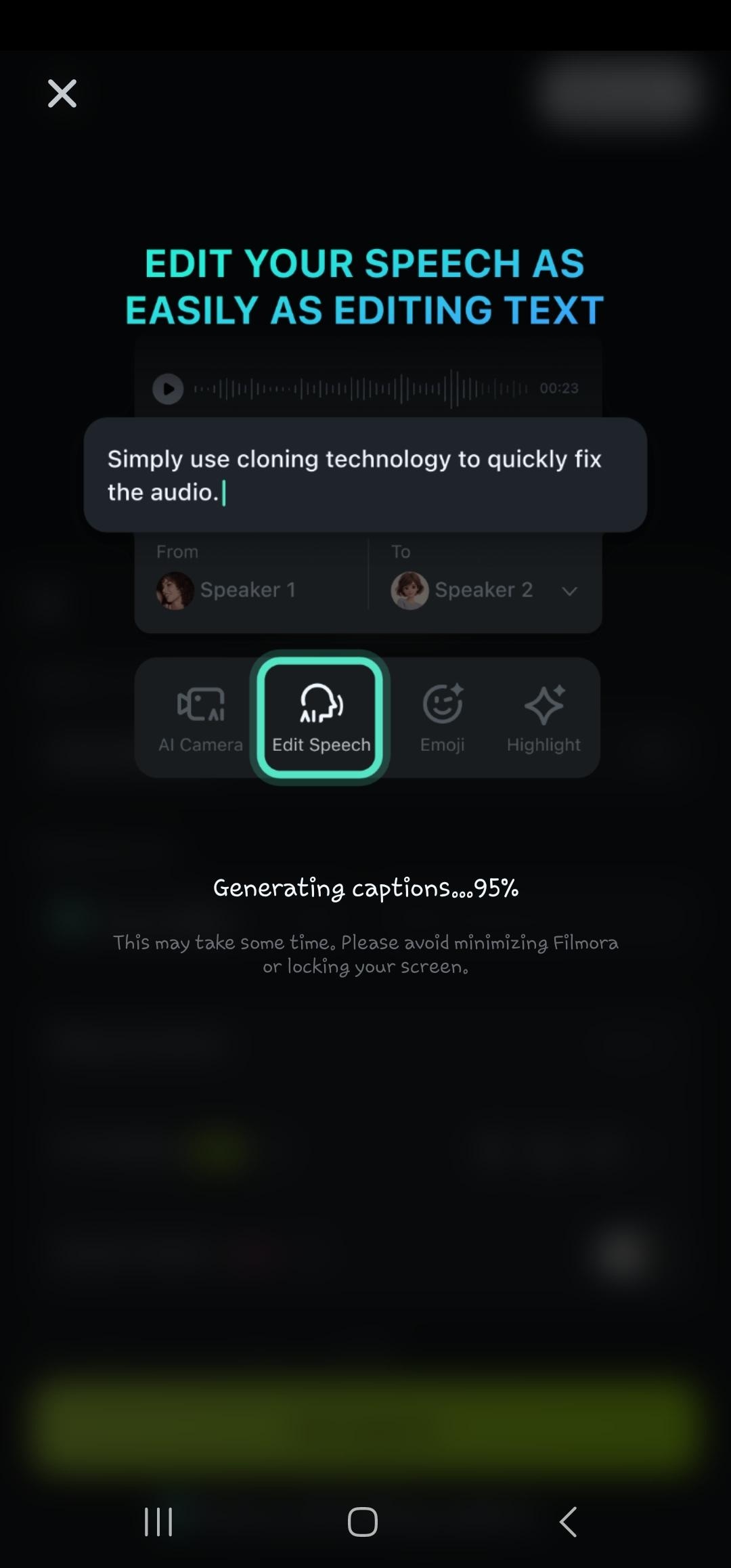
- Step 5: Wait while the AI processes the voice-to-text
- Step 6: Double-click on the generated text in the timeline to navigate to the edit speech option. Here you can add animation, change the text template, font, style, art, etc.
- Step 7: Export the video
Part 4: Where Can I Use Speaker Recognition Apps?

Speaker recognition in Python is transforming diverse industries, no doubt. This technology provides a fast and reliable way to identify voices in videos or audio files. It is becoming a fundamental part of different industries. Below are areas where these apps are applicable.
- Smart assistants and voice-controlled devices. Apps like Siri, Alexa, and Google Assistant use speaker identification to distinguish voices. This enables personalized responses, secure access, and custom voice commands for different users.
- Security and voice authentication. Many companies use speaker identification to verify users and prevent fraud. It eliminates password dependency while improving data protection and user convenience.
- AI-powered transcription and meeting notes. Speaker recognition helps applications like Otter.ai differentiate speakers. This increases the accuracy of transcription, especially those with several voice notes.
- Call centers and customer support. Call centers use speaker recognition in Python to enhance customer authentication and detection. AI-powered systems identify callers by voice, reducing the need for manual identity verification. This improves security, efficiency, and response times in customer service.
- Healthcare and accessibility. Hospitals and healthcare apps use speaker identification for secure patient authentication. Voice-based AI tools help individuals with limited mobility access devices without physical interaction. Python speaker recognitionensures secure medical access and enhances patient care.
Conclusion
Python is one of the most popular languages for speaker and voice identification. It provides powerful libraries like SpeechRecognition, PyAudio, Librosa, and Pico Voice Eagle SDK.
These tools enable high accuracy and real-time speaker identificationin Python. This makes it the best option for developers, AI researchers, and security applications. Filmora offers an easier alternative for those without programming skills. It provides speech-to-text conversion, voice editing, and speaker recognition without requiring Python coding.
Try Filmora’s AI-powered tools for automatic voice editing and transcription. They make the process fast and friendly.
secure download