


 100% Security Verified | No Subscription Required | No Malware
100% Security Verified | No Subscription Required | No Malware


 ChatGPT
ChatGPT
 Perplexity
Perplexity
 Gemini
Gemini
 Claude
Claude
 Grok
Grok

English speech-to-text conversion is the process of turning spoken language into text. So many English text-to-speech tools can do this conversion quickly, allowing users to access information, help people communicate, and improve the shareability of video content. Text-to-speech technology has improved so much since it appeared.
In the past, this technology was reserved only for government projects and some of the largest private companies. However, today, it’s widely available to everyone, and that’s why there are so many options available. Today, we’ll help you understand how STT works, which features to look for, and how to pick the right option for your needs.
Furthermore, we’ll also share some tips and step-by-step instructions on how to use English text-to-speech generators. So, let’s start.
In this article
What Is the Technology Behind English Speech-To-Text Solutions?
English text-to-speech tools use a combination of advanced technologies that work in sync to convert spoken language into text. They accurately recognize what the voices are saying and transpose these sounds into appropriate text.
Natural Language Processing

Natural Language Processing technology recognizes and processes human language while analyzing grammar, syntax, and context in spoken languages. This technology refines transcriptions, corrects errors, and identifies sentence structures.
Neural Networks
Neural networks and deep learning technologies improve the accuracy of the result through training on large datasets of spoken and written languages. These networks are designed to learn all the patterns from audio data and help improve overall transcription and recognition over time.
Phonetic Algorithms
STT tools use various phonetic algorithms to break down speech into phonetic sound units and map them with the correct text. The models use linguistic knowledge to understand pronunciations, dialects, and natural speech variations.
Automatic Speech Recognition

Automatic speech recognition (ASR) is one of the most essential technologies in speech-to-text tools. It converts spoken sounds into text using audio analysis. ASR technology breaks down speech elements into tiny units and compares them against different language models for better accuracy and prediction.
Noise Reduction Algorithms
Most audio or video files with speech don’t have clear sounds. That’s why speech-to-text solutions use noise reduction algorithms to better understand what is being said. At the same time, these technologies clean up the audio and refine the signals to improve speech pattern recognition.
Voice Detection
Most speech-to-text tools use Voice Activity Detection to understand which parts of the audio signal have speech. VAD algorithms quickly determine when someone is speaking and can guide the system to focus on the areas relevant to transcription. They also perform speech segmentation to divide audio into meaningful units.
Main Features of Modern English Speech-To-Text Tools

Modern English speech-to-text tools are more sophisticated than their predecessors. They use advanced technologies to give more refined results and ensure usability, accessibility, and accuracy. Here are some key features you can expect:
- High accuracy: Modern speech-to-text solutions can guarantee 90% accuracy rates with the latest advanced speech recognition models. That means users get reliable transcriptions that require little manual editing.
- Multi-language support: Modern speech-to-text solutions support an average of ten languages. In other words, they work with full capabilities in multiple languages, which increases versatility and flexibility.
- Speech enhancement and noise reduction: Most speech-to-text solutions can work with noisy audio files. They clean up background noise and can distinguish speech from noise. Overall, this leads to better accuracy and less need for manual editing.
- Automatic formatting and punctuation: Modern English speech-to-text tools automatically detect silence and pauses in audio speech and insert punctuation like question marks, commas, and periods based on the context and language structure.
- Custom vocabulary: Many STT products allow users to train the program with specific language, industry-specific jargon, or names. It’s useful for specialized industries like legal or healthcare where unique terminology is used.
- Multi-speaker recognition: Modern English speech-to-text solutions can identify and label multiple speakers in the conversation. This feature is ideal for transcribing interviews or meetings and creates more organized text.
- Text editing: Some tools let users generate and edit text in multiple ways. The text can be converted to different formats, added to videos, stylized, animated, etc. At the same time, these tools also offer real-time editing and control of transcriptions.
Top English Speech-To-Text Tools to Consider
Wondershare Filmora

Wondershare Filmora is a modern video editing software with some of the latest AI technologies. It features a powerful speech-to-text functionality that can transcribe videos accurately with just a single click.
It works with 27 languages and transcribes them into text with great accuracy. It will automatically generate text and sync it with a video or audio. On top of that, it has various editing features, allowing you to use, configure, and style your text for future use.
Otter.ai
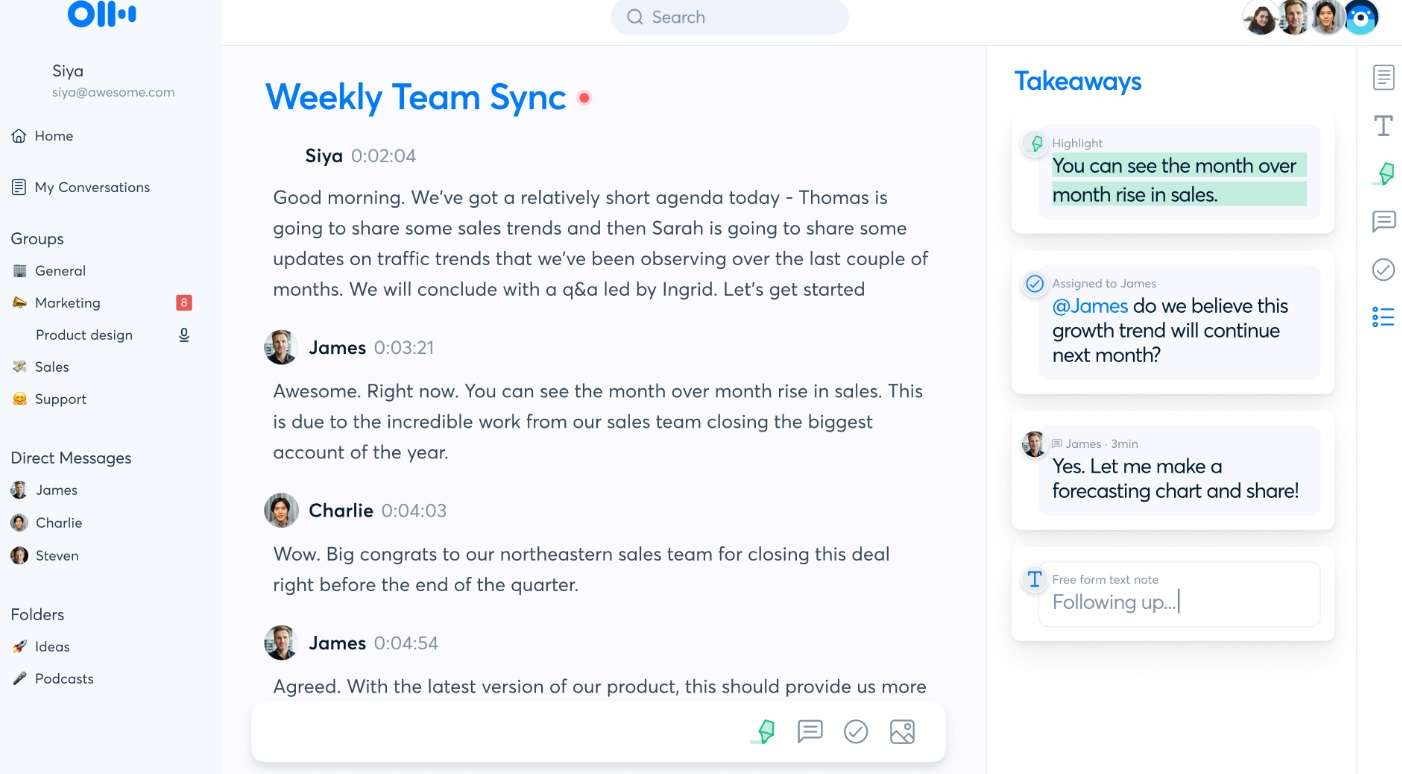
Otter.ai is a meeting assistant equipped with all kinds of bells and whistles, including speech-to-text. It offers real-time transcription capability and has speaker identification, allowing you to document meetings with ease. It can extract keywords from the transcribe and create automated summaries.
It synced effectively with various conferencing tools, including Zoom. It’s a great transcription tool but doesn’t offer many text-editing options.
Rev
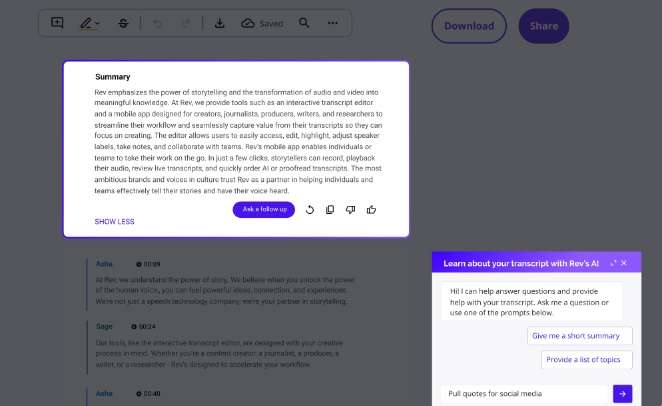
Rev offers AI-based and human transcriptions. It’s very accurate, especially when used for human transcription. Rev is a versatile speech-to-text solution with video and audio input. It is one of the few speech-to-text tools that offers captioning and editing tools.
Rev has an excellent web interface and several collaboration tools to improve teamwork. It offers a fast turnaround and is made for professionals who must transcribe large volumes of material.
Microsoft Azure
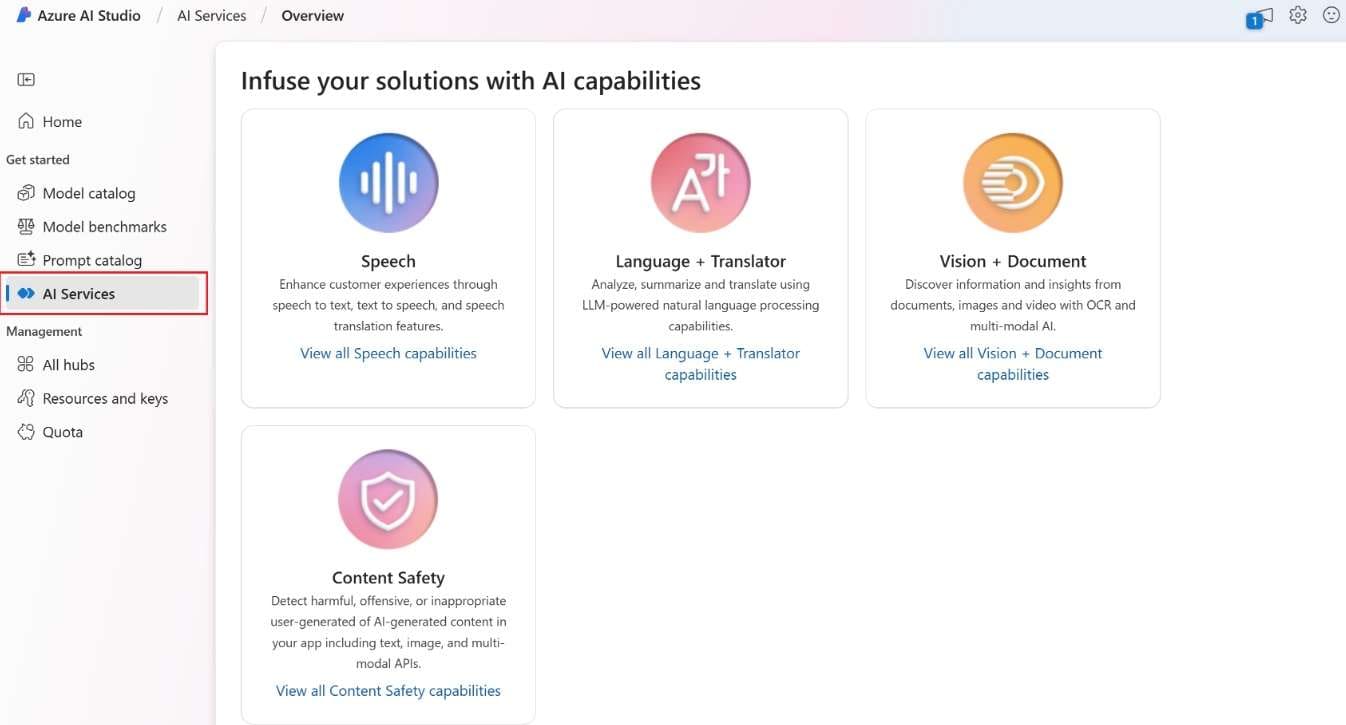
Microsoft Azure is a public cloud platform that offers various services, such as networking, storage, virtual computing, analytics, and more. It delivers many AI capabilities, including speech recognition, adaptive learning, and custom voice models.
It offers real-time transcriptions and is very popular with larger organizations because of its batch transcription capabilities. It can recognize speakers and supports many languages.
Main Use Cases of English Speech-To-Text Software
English speech-to-text transcriptions have many applications for personal and business use. Here are some of the primary use cases:
1️⃣Adding Subtitles to Videos
English speech-to-text can be used on whole movies or TV show episodes to generate accurate and synced subtitles. For example, with Filmora, you can create SRT files in minutes without editing the titles manually.
2️⃣Meeting Transcriptions
English speech-to-text solutions quickly transcribe virtual calls, conferences, and meetings, allowing business professionals to quickly document what was said and create summaries they can send to key stakeholders.
3️⃣Creating Content
Bloggers, writers, content creators, and social media influencers can dictate reports, blogs, or articles without typing. Furthermore, they can add captions to videos to make them more accessible to people with hearing impairments.
4️⃣Language Learning and Translation
Speech-to-text tools can translate and transcribe spoken English for use in language learning or multilingual settings. Many companies, translators, and language learners use speech-to-text to understand what is being said, improve pronunciations, and memorize how specific words are written.
Tips for Getting the Best Results With English Speech-To-Text Solutions

Here are some general tips on how to use English speech-to-text solutions for the best possible results:
Use Clear and Quality Audio
Whether you’re transcribing in real time or feeding software with audio files, it’s essential to use quality input. The better the audio quality, the better the results will be. Even though modern English speech-to-text tools can remove noise, it can still cause issues.
Avoid Slang and Use Correct Pronunciation
Avoid using jargon or slang unless the software is trained to recognize them. Furthermore, proper pronunciation is essential for getting accurate text conversion. If you pay attention to these things, you will need less manual editing.
Rely on The Training Features
Take the time to train the software for the specific type of speech you plan on using. Investing some time in training can be the differentiating factor for future transcriptions and will affect the overall accuracy and quality.
How to Use English Speech-To-Text Generator
Here are the exact steps on how to use English speech-to-text in Filmora:
Step 1: Open Filmora and click New Project in the startup window.
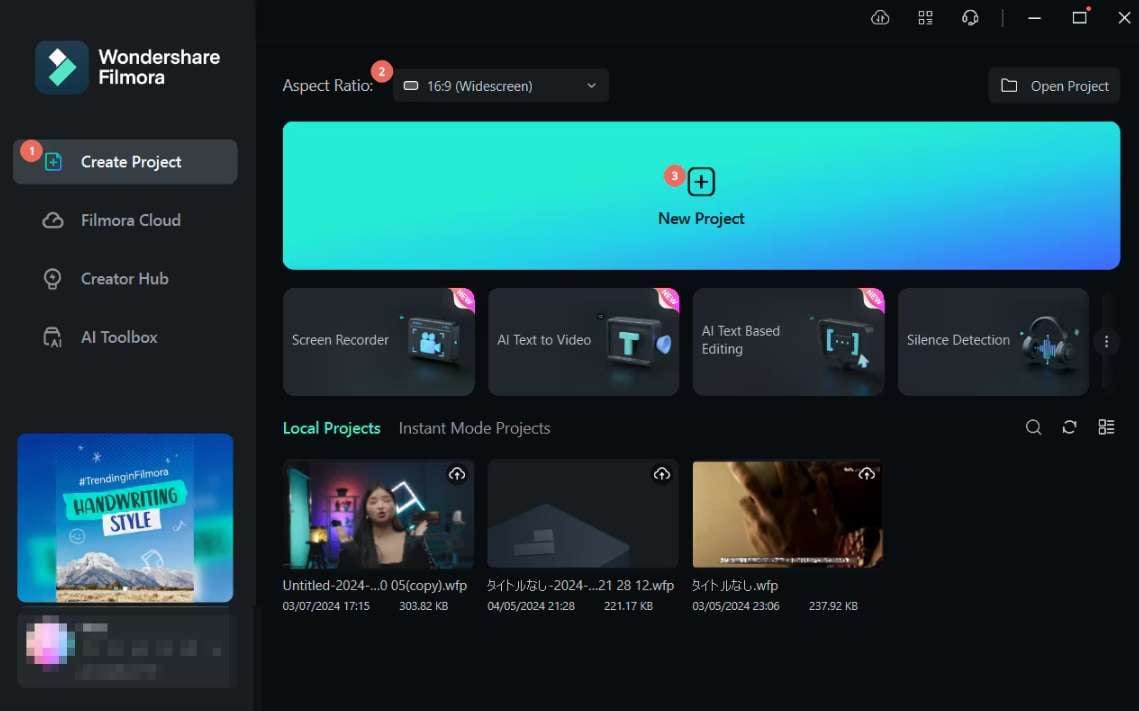
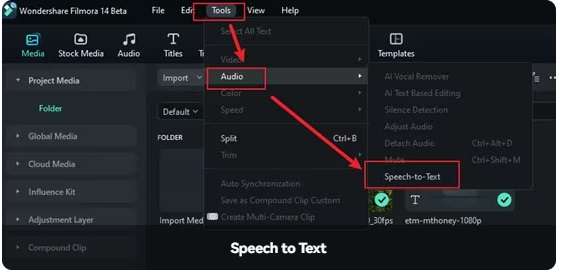
Step 2: Import a video or audio file into Filmora and drag it to the timeline. Left-click the video/audio track and go to Tools > Audio > Speech-to-text.
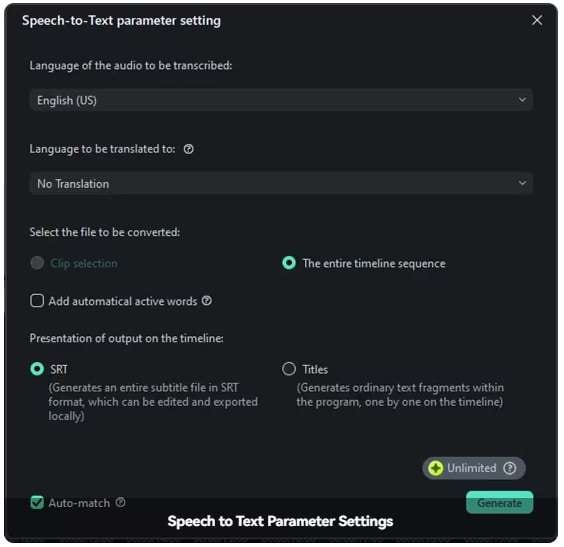
Step 3: Select English as the language, add a language to be translated to if needed, select the out format, and click Generate when ready.
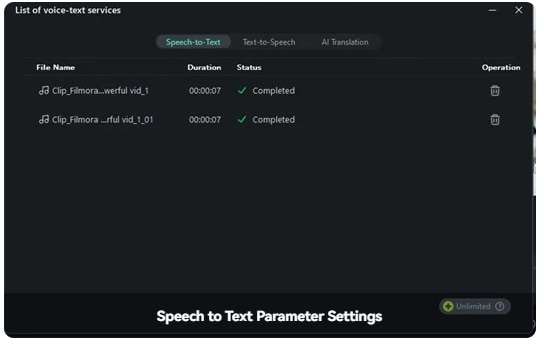
Step 4: Wait until the process is completed.
Conclusion
English speech-to-text tools have gone a long way. Tools like Filmora can translate English speech into different languages. These tools work with many different languages, and their accuracy keeps improving. That’s why more individuals and organizations rely on them for their workflows.
Take the time to try out these tools and see just how effective they are. Follow the exact steps we’ve shared, and we guarantee you’ll be amazed by the results.
